前两天看了一下Context Encoder的相关论文,这个东西可以用于理解图片的语义,比如填补图片的缺失区域。我只研究出了它大概怎么做的,有些细节还没搞懂,以此记录一下。
Overall
整体网络由两部分构成,分别是编码器(Encoder)和解码器(Decoder),中间由Channel-wise fully-connected layer 连接,如下图所示。
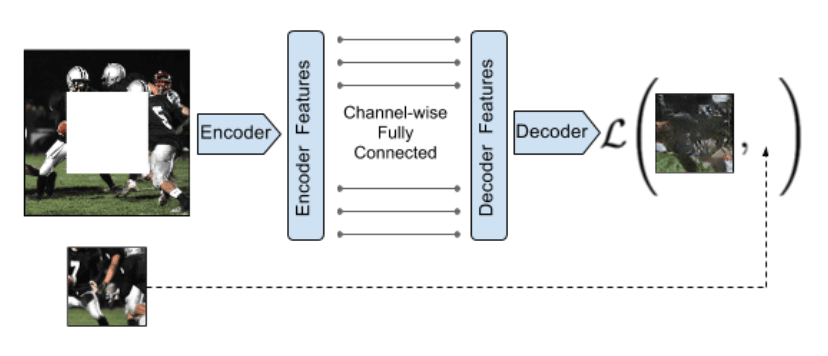
Encoder
编码器用于从图片提取高维特征,其结构来自 AlexNet 的前5个卷积层和相应的池化层(pool5),并随机初始化权重。
Channel-wise fully-connected layer
为了能综合各个 feature map 的信息,通常是用全连接层(fully-connected layer)来做,但是这么做的话参数太多了,训练比较困难,于是就采用分组的策略。
假设有 \(m\) 个 feature map,每个feature map的大小是 \(n*n\),该层输出也是 \(m\) 个 feature map,每个大小为 \(n*n\), 但是与全连接不同的是,每个feature map 只和自己全连接,不和其他feature map连接,这样的话需要的参数是 \(mn^4\),相较于全连接层的 \(m^2n^4\)。
Decoder
解码器是使用编码器的特征生成缺失的图像。生成图像使用 up-convolutinal/upsampling layers,每层后跟一个线性整流(ReLU)层。
up-convolutinal可以被理解为先反池化再卷积(unpooling+convolution)。反池化就是池化的逆过程,把一个大小为 \(s*s\) 的feature map反池化,只需把每个像素变为 \(s*s\) 的像素块,只有每个块左上脚的像素和原来一样,其他值为0,如 \(s = 2\) 的反池化如下图(左)所示:

它还可以被理解成是步长(stride)为小数的卷积层:正常的卷积层步长为一个整数 \(f\),那么逆卷积层(deconvolutin/up-convolutinal layers) 就相当于是步长为 \(\frac{1}{f}\) 的卷积层。实现逆卷积层的一个自然办法就是实现一个步长为 \(f\) 的向后卷积(backwards convolution),只用简单地 reverses the forward and backward passes of convolution(论文里这么写的,不是很懂什么意思)。
解码可以通过添加一系列这样的 upsampling layers 实现,直到生成的图像达到目标大小。
Loss function
整个网络的损失函数由两部分组成,一部分是重建损失(reconstruction loss),另一部分是对抗损失(adversarial loss)。
重建损失是一个L2损失,为了捕获缺失区域的整体结构并且保持上下文的连续性,但是L2损失在预测时趋向于均值,如果只用L2损失,预测出来就非常模糊,如下图(c)所示。对抗损失就是为了使预测结果更加真实,它有从分布中挑选出一个特定模式的效果。

对于每个图片 \(x\),送给整个编码器 \(F\) 去训练,产生最终结果记为 \(F(x)\)。令 \(\hat{M}\) 为一个二进制掩码矩阵,图片的缺失区域值为1,其他区域为0 。那么我们实际送给编码器训练的图片就是 \((1-\hat{M})\odot x\) ,其中 \(\odot\) 为按位相乘。
Reconstruction Loss
那么重建损失的表达式就为: \[ L_{rec}(x) = ||\hat{M}\odot(x-F((1-\hat{M})\odot x))||^2_2 \] 论文中说使用L1损失和L2损失差别不大。尽管这个损失很简单,但它能促使解码器生成预测目标的大致轮廓,一般不能生成高频的细节,如上图(c)所示。我们觉得出现这种情况是因为预测一个分布的平均值对L2损失来说更加“安全”,因为这样能最小化每个像素的平均误差,但这样就会导致模糊的结果。
Adverarial Loss
为了减轻上面的问题,我们又加了一个对抗损失。
对抗损失基于 Generative Adversarial Networks(GAN),原始GAN是这样的:为了一个使生成模型 \(G\) 学习某种数据分布,GAN同时训练一个与之对抗的判别模型 \(D\) 来提供 \(G\) 的损失。\(G\) 和 \(D\) 都是 parametric function,其中 \(G\) 是一个从噪声分布 \(Z\) 到数据分布 \(\chi\) 的映射。学习过程就是判别模型 \(D\) 接收 \(G\) 的输出和真实样例作为输入,并尝试区分它们,输出哪个是真实样本哪个是生成出来的,而 \(G\) 的目标就是通过输出结果尽可能接近“真实”来混淆 \(D\) 的判断。
所以 GAN 的目标就为: \[ \min_G\max_D E_{x\in \chi}[\log(D(x))] + E_{z\in Z}[\log(1-D(G(z)))] \] 这里边的 \(E\) 是什么意思没有搞懂,感觉不像是数学期望的意思。如果把 \(G\) 和 \(D\) 的目标分开来写的话,那 \(D\) 的目标就是: \[ \max_D E_{x\in \chi}[\log(D(x))] + E_{z\in Z}[\log(1-D(G(z)))] \] \(G\) 的目标是: \[ \max_G E_{z\in Z}[\log(D(G(z)))] \] 回到我们的问题,所以 context encoder 的对抗损失就是: \[ L_{adv} = \max_D E_{x\in \chi}[\log(D(x)) + \log(1-D(F((1-\hat{M})\odot x)))] \] 这个目标使得整个编码器的输出看起来更加真实。
Joint Loss
所以整体的损失函数就定义为: \[ L = \lambda_{rec}L_{rec} + \lambda_{adv}L_{adv} \] 在填补图片缺失区域这个问题中,超参数的选择分别为 \(\lambda_{rec} = 0.99\) 和 \(\lambda_{adv} = 0.01\)。
整个模型的大概怎么做的就是这样了,具体细节还需要在看论文和代码。
附:
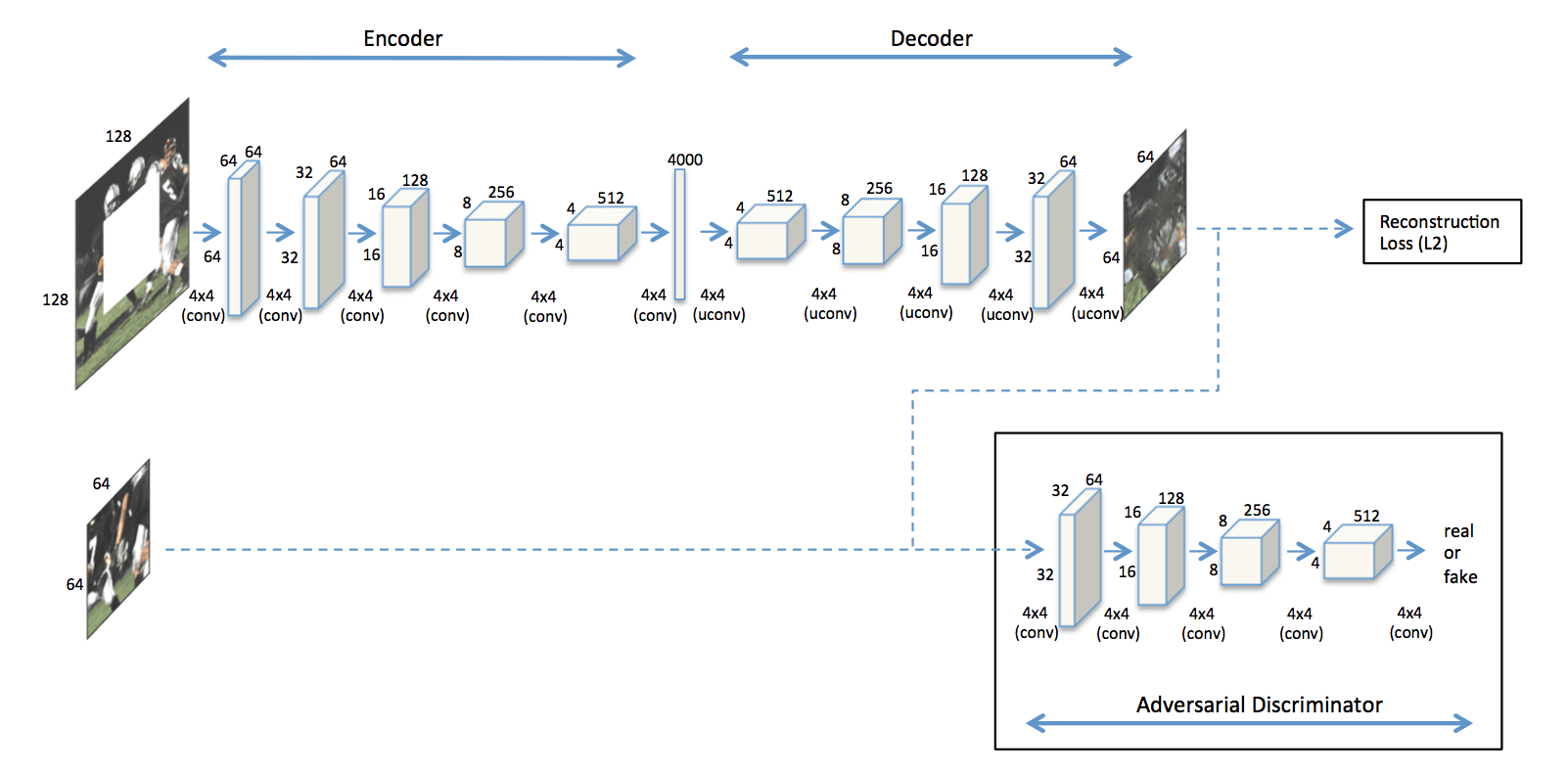
针对Inpainting任务的具体模型